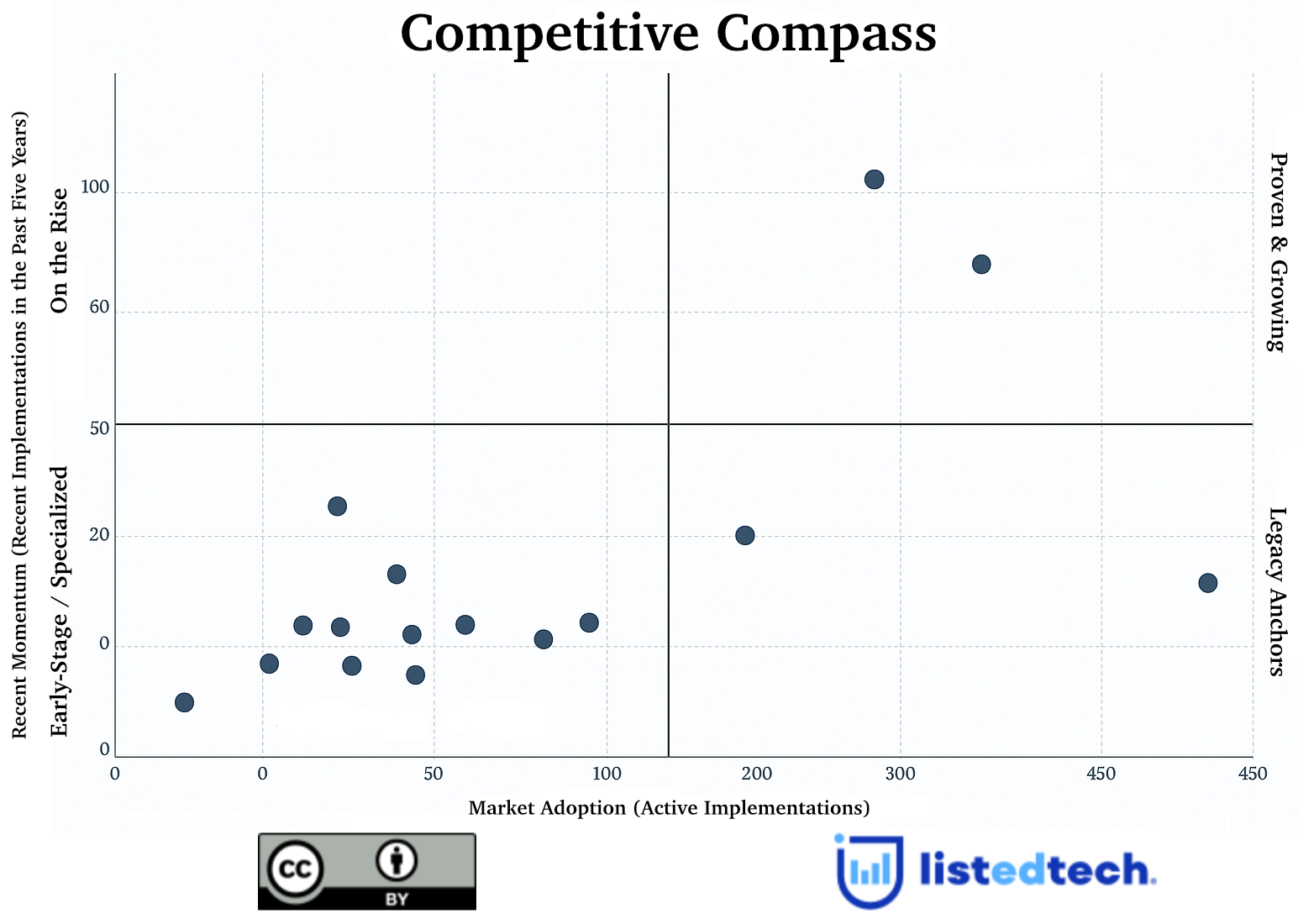
ListEdTech is the leading company in the EdTech space with unmatched detail on education software implementations. We provide comprehensive, in-depth data for both Higher Education and K-12 institutions. Our team meticulously reviews millions of data points annually, and every new entry in our database is validated by an employee to ensure the highest level of data quality and reliability.
What Information Do We Gather?
Since 2014, we’ve specialized in tracking IT systems used across the education sector. Our dataset includes:
- Information on over 81,000 institutions worldwide (degree type, public or private, enrollment).
- Detailed profiles of 2,200+ EdTech companies (mergers, partnerships, and corporate data) and their 4,100+ products (acquisitions, contracts with institutions, active customer base).
- For each system implementation, we aim to capture whether it’s a primary or secondary system, along with its implementation and decommission dates.
Our team works diligently to eliminate bias, frequently updating and validating our data at its source to maintain the accuracy of over 5.2 million data points. While no dataset can offer a complete market picture, our rigorous methods help ensure fair representation of all solutions.
How Do We Update Our Database?
Our work is divided into four stages:
- We continuously monitor publicly available sources to track new IT system implementations in education. We gather data from university and company websites, social media, press releases, as well as legal documents like RFPs, contracts, and board approvals.
- Daily, we process over 25,000 new alerts. These are initially filtered by machine learning algorithms to remove irrelevant data, followed by manual reviews by our team of 20+ full-time employees, ensuring that new product lines are accurately added or updated in our database.
- Every month, our data quality experts audit over 1,000 database entries to ensure the accuracy of our information.
- Annually, we conduct a comprehensive review to confirm that institutions are still using the identified systems. As a result, our 300,000+ data lines (comprising more than 3 million data points) remain precise and up-to-date.
ListEdTech Historical Data Points
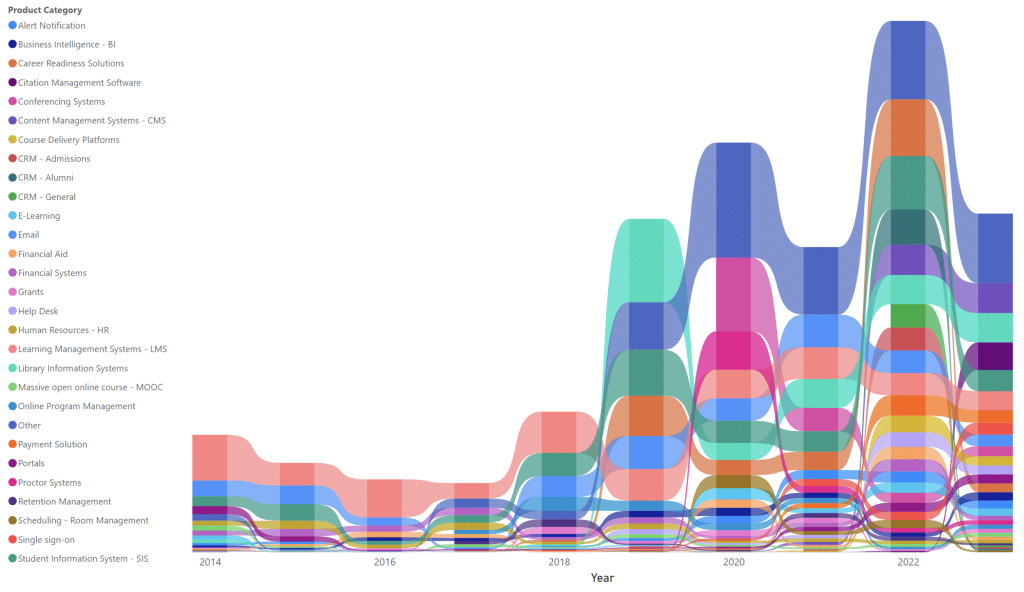
The graph above illustrates the evolution of our database over the past decade and the ranking of discovered implementations by product category. Key takeaways include:
- Consistent Growth: Between 2014 and 2022, the number of discovered implementations has steadily increased, with an average annual growth rate of 41%.
- Sharp Growth Spike: From 2018 to 2019, discovered implementations surged by 70% compared to the previous year.
- Broader Category Coverage: While learning management systems dominated early discoveries, categories such as library management systems, email, and career readiness solutions have seen the most significant additions since 2019.